A blob-carrying transaction contains two new fields that a typical Ethereum transaction does not:
a bid that defines how much the transaction submitter is willing to pay to have their blob-carrying transaction included in a block (max_fee_per_blob_gas), and
a list of references to the blobs included in the transaction (blob_versioned_hashes).
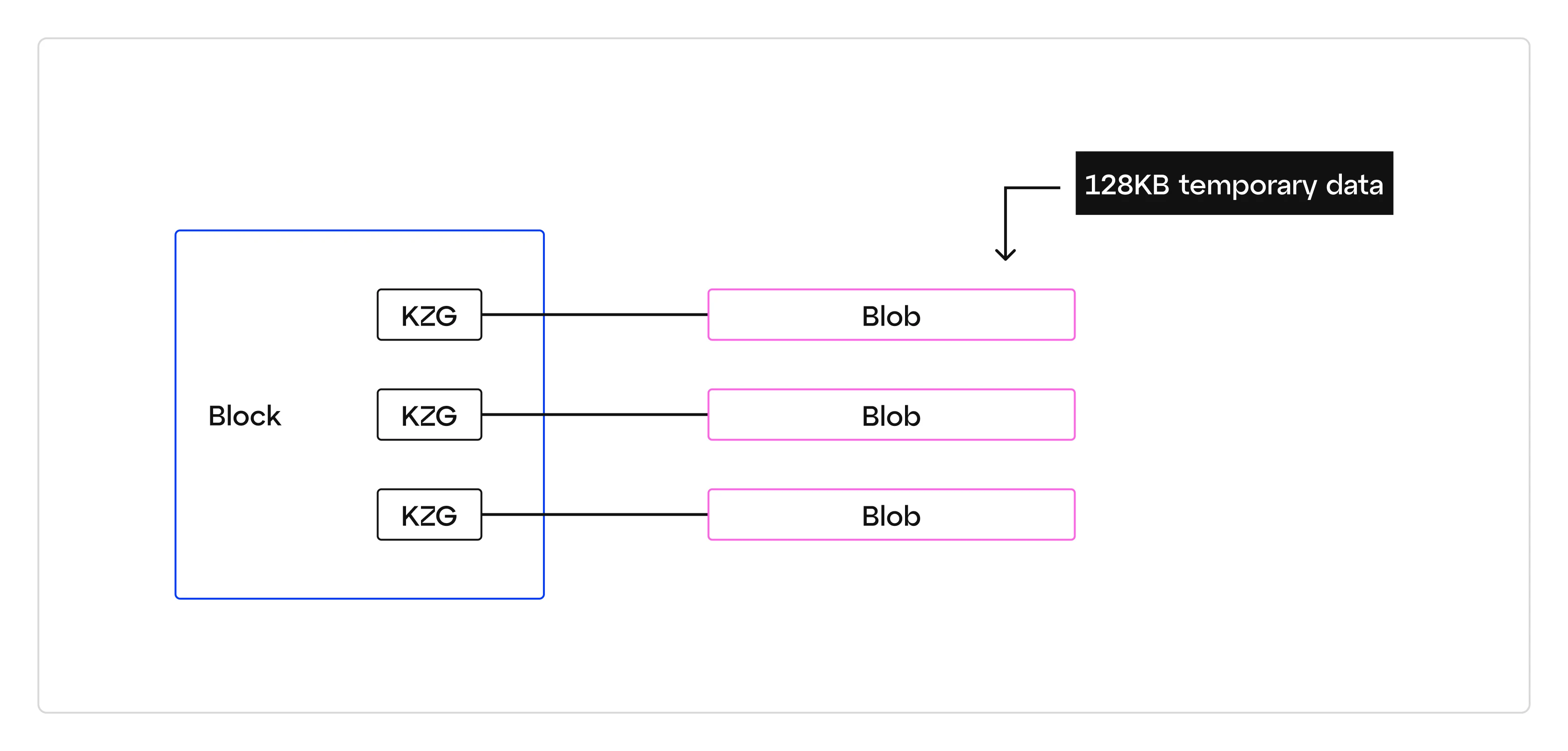
Notably, the blob-carrying transaction doesn’t actually include the blob data; only a reference to it in the blob_versioned_hashes field (item 2 above). Technically, this reference is a hash of a KZG commitment to the blob, but for our purposes, it's sufficient to think of this as a fingerprint that is unique to each blob and that can be used to tie each blob to a blob-carrying transaction.
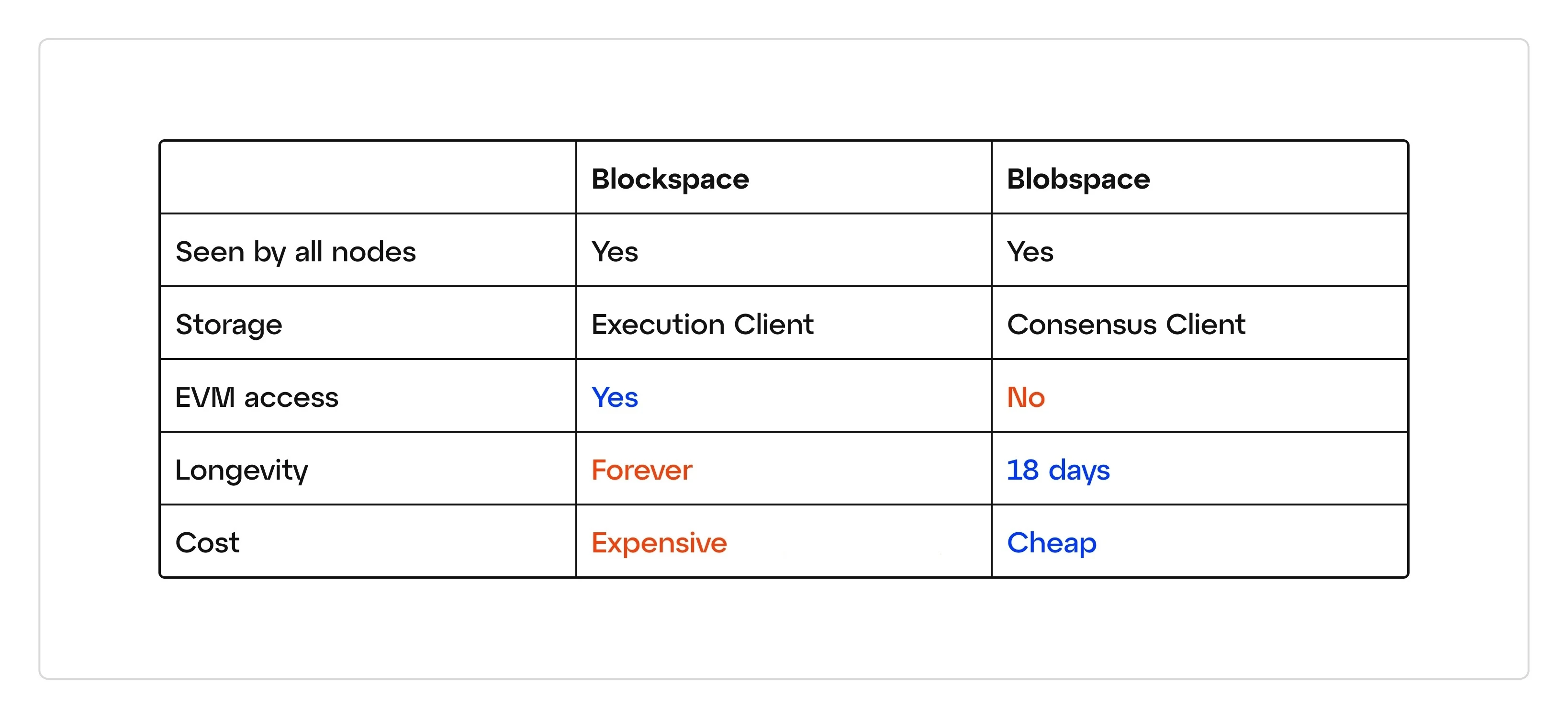
Since only this reference to each blob exists within a given block, the L2 transactions contained in each blob are not, and can not be, executed by Ethereum’s execution layer (aka, the EVM). This is the reason why blob data of a given size (128KB per blob) can be posted to Ethereum by a rollup sequencer more cheaply than regular Ethereum calldata of similar size - blob data does not need to be re-executed by the Layer 1 (Ethereum, in this case). The actual data that makes up each blob is circulated and stored exclusively on Ethereum’s consensus layer (i.e. beacon nodes), and only for a limited period of time (4096 epochs, or ~18 days).
Technically, blobs are vectors of data that are made up of 4096 field elements, with each field element being 32 bytes in size. Blobs are constructed in this way so that we can create the succinct cryptographic references to them that are found in blob-carrying transactions, and so that blobs can be represented as polynomials. Representing blobs as polynomials allows us to apply some clever mathematical tricks - namely, erasure coding and data availability sampling – that ultimately reduce the amount of work each Ethereum consensus node must perform to verify the data in a blob. A full explanation of the mathematics that enable all of this is out of scope for this post, but Domothy’s Blockspace 101 article provides an accessible starting point.
Making Use of the Blob
How will rollup sequencers make use of blobs?
Ultimately, rollup sequencers need to post some data to Ethereum mainnet. Today, they do this by posting batched transaction data as Ethereum calldata, which is an arbitrary data type and can be quite expensive. After EIP-4844 is implemented, rather than submitting their data to mainnet as calldata, rollup sequencers can sign and broadcast the new, “blob-carrying” transaction type and achieve the same goal - having their data posted to, and therefore secured by, Ethereum mainnet.
EIP-4844’s New Precomplies
Proto-Danksharding also introduces two new precompiles, the blob verification precompile and the point evaluation precompile, that are meant to be used by optimistic and zk-rollups respectively. These precompiles are what’s used to verify that the data in a blob matches the reference to the blob included in the blob-carrying transaction (i.e. the versioned hash of the KZG commitment to the blob).
To more specifically outline how each rollup will use these precompiles, we’ll quote EIP-4844 itself:
“Optimistic rollups only need to actually provide the underlying data when fraud proofs are being submitted. The fraud proof submission function would require the full contents of the fraudulent blob to be submitted as part of calldata. It would use the blob verification function to verify the data against the versioned hash that was submitted before, and then perform the fraud proof verification on that data as is done today.”
"ZK rollups would provide two commitments to their transaction or state delta data: the KZG in the blob and some commitment using whatever proof system the ZK rollup uses internally. They would use a commitment proof of equivalence protocol, using the point evaluation precompile, to prove that the KZG (which the protocol ensures points to available data) and the ZK rollup’s own commitment refer to the same data.”
Blob Market
While the number of blobs that may be attached to a block is dynamic (ranging from 0-6), three blobs will be targeted per block. This targeting is conducted via a pricing incentive mechanism not dissimilar from EIP-1559; the pricing of a blob gets more expensive when there are more than three blobs attached to a block. Reciprocally, the blob price gets cheaper when there are less than three blobs set to be attached to a given block.
Specifically, the costs for blob transactions from one block to the next can increase or decrease by up to 12.5%. The degree to which these price movements will approach +/- 12.5% per block is calculated by the total amount of gas used by all attached blobs, which necessarily scales with the increase in blobs, since all blobs will be 128KB in size regardless if they are completely filled or not.
This pricing calculation functions via a running gas tally: if blocks consistently host more than 3 blobs the price will continually increase.
As the blob market fluctuates via the dynamic pricing model described above, layer 2 contracts will need near real-time pricing information of the blob market to ensure proper accounting. Alongside EIP-4844, the corresponding EIP-7516 will ship to create the opcode BLOBBASEFEE, which rollups and layer 2s will utilize to query the current blob base-fee from the block header. It is an inexpensive query, requiring only 2 gas.
Blob Expiry
A blob is transient and designed to remain available for exactly 4096 epochs, which translates to roughly 18 days. After this expiry, the specific data within the blob will no longer be retrievable from the majority of consensus clients. However, the evidence of its prior existence will remain on mainnet in the form of a KZG commitment (we’ll explain these later). You can think of this as a leftover fingerprint, or a fossil. These cryptographic proofs can be read to prove that specific blob data once existed, and was included on Ethereum mainnet.
Why was 18 days chosen? It’s a compromise between cost of increased state size and liveness, but the decision was also made with optimistic rollups in mind, which have a 7 day fault proof window. This fault proof window was therefore the minimum amount of time blobs must remain accessible, but ultimately more time was allotted. A power of two was chosen (4096 epochs is derived from 2^12) for simplicity.
Even though the protocol will not mandate blob storage beyond 18 days, it is highly likely that certain node operators and service providers will archive this data. That is to say, a robust blob archive market is likely to emerge off-chain, despite the protocol not mandating permanent inclusion on-chain.
Blob Size
Each blob attached to a block may hold 128KB of temporary data, although a given layer 2 may not completely fill a given blob. Importantly, even if a layer 2 does completely fill a blob, the “size” of the blob being attached to the block will always be 128KB (the unused space must still be accounted for). Therefore, given the range of potential blobs per block, EIP-4844 may increase the data associated with a block by up to 768KB (128KB per blob x 6 possible blobs).
Immediately after EIP-4844, layer 2s will not collectively fill blobs. In fact, data that a layer 2 batches into blob space will not have a relationship with the data a different layer 2 batches. It’s worth noting that protocol upgrades or future innovations, such as shared sequencers, or blob sharing protocols, may allow L2s to collectively fill a given blob.
This is, of course, currently the case with blockspace, where protocols, rollups, dApps, and user transactions are collectively bundled together as appropriate by size and priority fee. Where this collectivization from a public mempool typically catered to consistently full, or near full blocks, it may be the case that rollups will less frequently bump up against the 128KB blobspace limit before a form of blob sharing is introduced.Not only will there be a single sequencer or organizer per blob (for now in our centralized sequencer world), but the relatively cheap nature of blobspace may enable less cramming and efficiency maxing compared to blockspace in the immediate term. In that way, blobspace efficiency may not be immediately close to the maximum until the rollup market and the rollups themselves further mature.
Neither will layer 2s be forced to use blobspace, and some may opt to occasionally continue to use blockspace, or even other data availability platforms. One can imagine many creative posting solutions depending on the need for data retrieval, and the market prices across each storage type.