Benchmarking Smart-Contract Fuzzers

Over the last few years, several robust smart-contract fuzzers, such as Echidna, the Foundry/Forge fuzzer, and Harvey, have been developed. In theory, this is great for developers since they could use all these tools to catch bugs. In practice, running and setting up all these tools is also quite a bit of effort. It would be great if they had some help deciding which fuzzer to focus on (at least initially).
Unfortunately, there is no way to know what fuzzer will perform best on a given codebase. While there are well-known benchmark sets for C-based fuzzers, such benchmark sets do not yet exist for smart-contract fuzzers. It is also unclear what contract systems to use as benchmarks and, more generally, how to make the comparison as fair as possible. For instance, different tools use different ways to check and report assertions.
Daedaluzz
We developed Daedaluzz, an automated tool for generating challenging benchmarks to avoid such issues. A key goal is to make it possible to compare as many different fuzzers as possible. For this reason, the benchmarks intentionally use a limited subset of Solidity to avoid language features that some tools could handle differently (or not at all).
Each generated benchmark contract contains many assertions (some can fail, but others cannot due to infeasible path conditions). A fuzzer can create sequences of transactions that make those assertions fail. We can measure a fuzzer’s performance by the number of distinct assertion violations found.
Simply put, the more issues a fuzzer finds in a benchmark contract, the better!
How does it work?
On a high level, each benchmark contract keeps track of the current position in a 2-dimensional maze of a fixed dimension (for instance, 7x7). Each transaction can move the current position to explore the maze. Some locations in the maze are unreachable (so-called “walls”), while others may contain a “bug” that can be found by the fuzzer when providing specific transaction inputs. Some of these bugs cannot be reached since the path conditions are infeasible (for instance, if their location is surrounded by walls).
The generated benchmarks try to capture two key challenges when fuzzing smart contracts:
- single-transaction exploration: code that can only be reached by satisfying complex transaction-input constraints
- multi-transaction exploration: code that can only be reached by first reaching a specific state of the contract through multiple prior transactions
We generated five benchmark contracts ourselves and made it super easy for you to generate your own by modifying the random seed and other parameters, such as the maze dimensions! You can also tweak the benchmark generator to create custom benchmark variants for fuzzers that do not support the default benchmark format; for instance, we tweaked it to produce custom benchmarks that Foundry can fuzz!
Daedaluzz is open source. Let us know if you have benchmarking ideas! We’re looking forward to contributions! 🚀We are already exploring possible extensions with a research group at TU Vienna.
Running different fuzzers
Setting up a fuzzer with a suitable configuration can be challenging. To make sure we’ve set everything up properly, we asked the developers for feedback (see the discussion on GitHub for Echidna and Foundry/Forge).
We tried several alternative fuzzer configurations to tune the fuzzer setup to get a fair comparison. For instance, tuning the initial Echidna configuration helped it find over twice as many violations! We also tried to set up Hybrid-Echidna, but it didn’t outperform vanilla Echidna. According to the developers, the tool is still experimental (see the corresponding Github issue), so we excluded it from the results below.
Note that we did not perform any tuning for Harvey. We designed Harvey to work out of the box for a wide range of smart-contract systems.
For running the fuzzers, we used a 48-core machine (Intel(R) Xeon(R) CPU E7-8857 v2 @ 3.00GHz) with 1.5TB of RAM running Debian GNU/Linux 11. For each fuzzer, we ran eight independent 8-hour fuzzing campaigns for each of the five benchmarks to account for randomness in the fuzzing process.
Results
Finally, let’s look at some results. The bar chart below shows the final number of violations (median over the independent campaigns) for the three fuzzers across all five benchmarks.
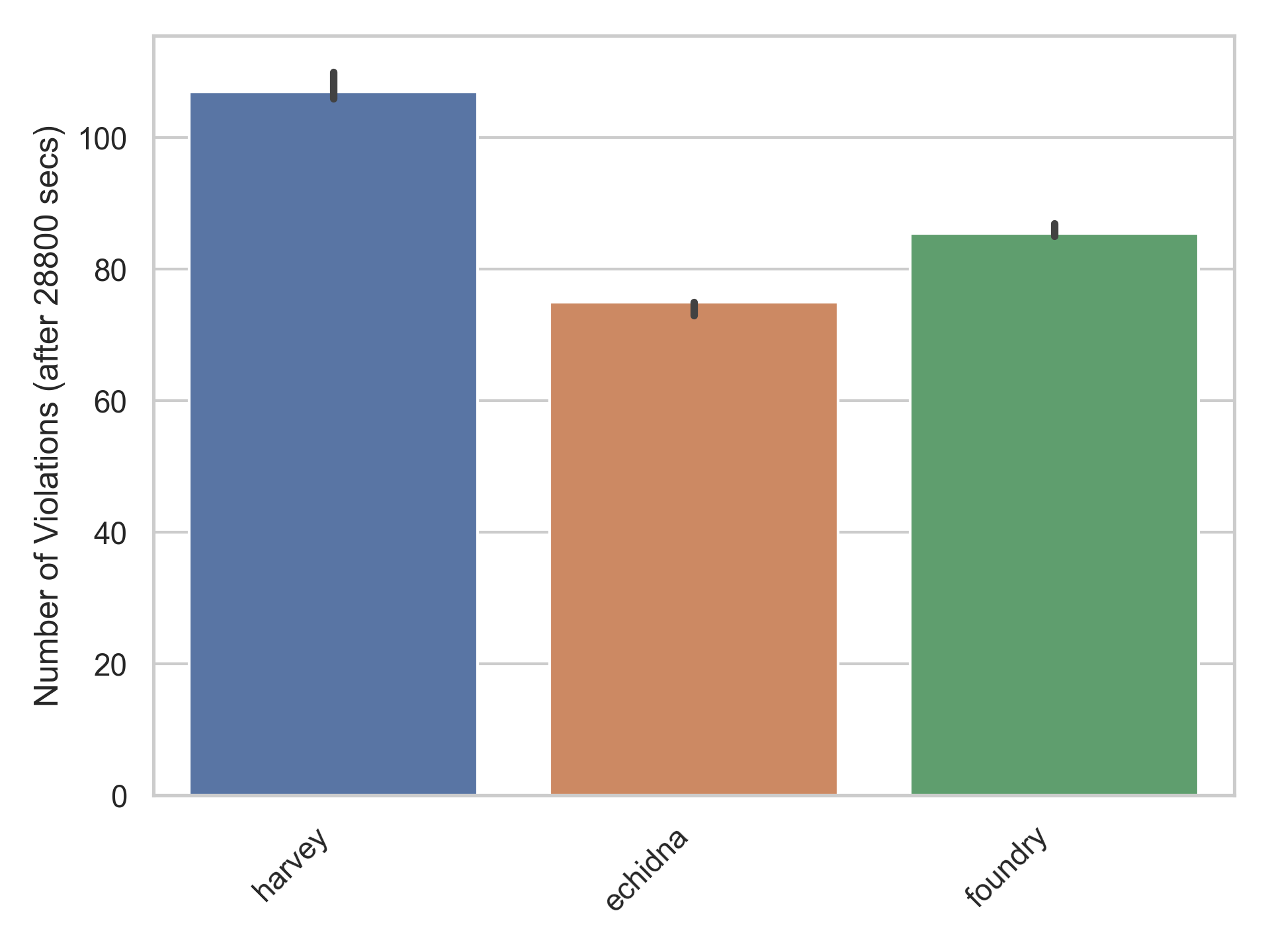
Overall, we can see that Harvey finds ~43% more violations than Echidna and ~25% more than Foundry/Forge. Let’s look at the number of violations over time for a more detailed comparison between Foundry/Forge and Harvey.
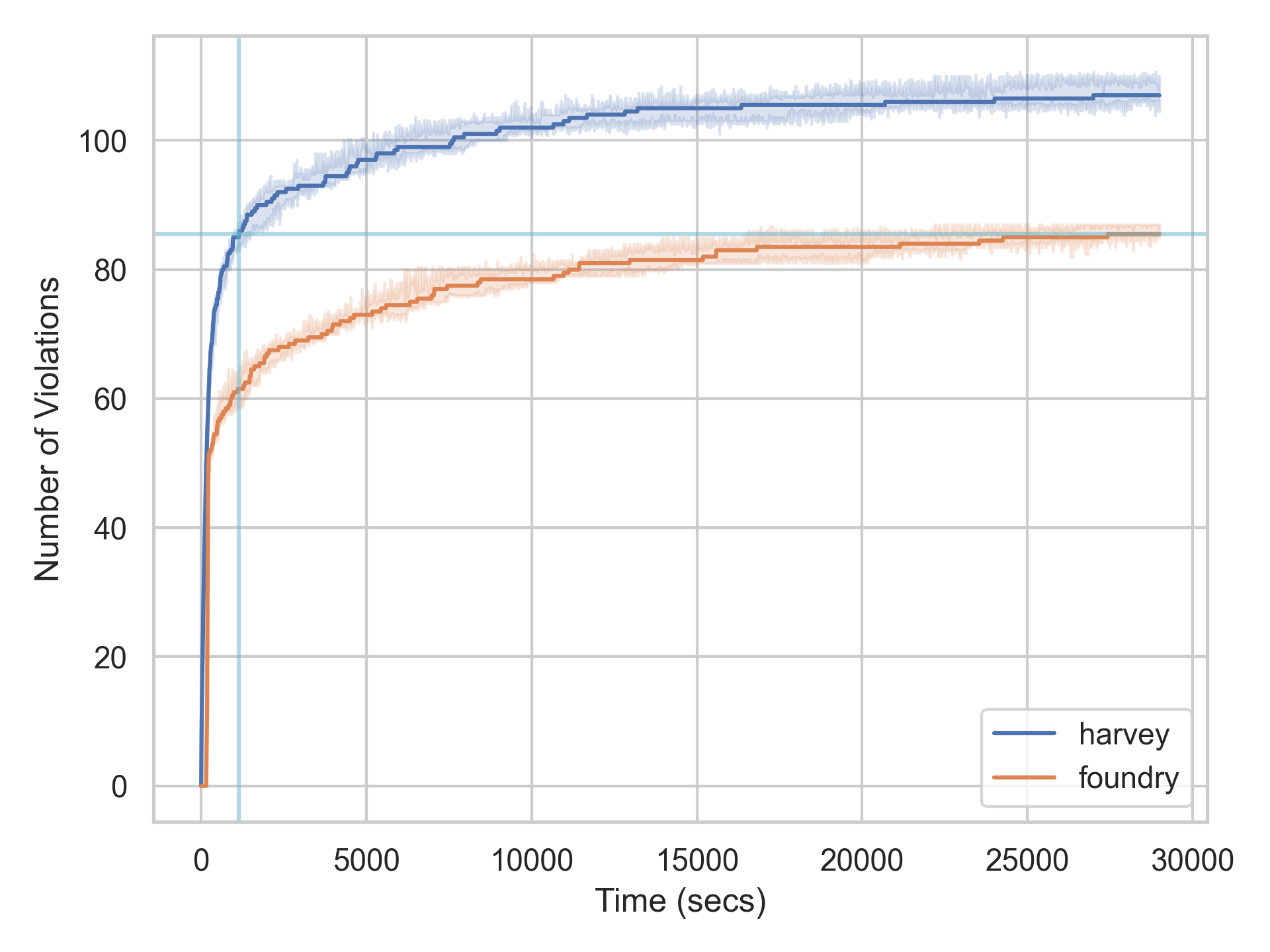
We can see that both fuzzers find a lot of violations initially, but over time it becomes increasingly challenging to find new violations. This is very typical for fuzzers since some violations are much more difficult to find. Harvey surpasses the final number of violations that are found by Foundry (after 8 hours) after only ~19 minutes. In other words, 19 minutes of fuzzing with Harvey are as effective as 8 hours of fuzzing using Foundry.
In summary, if you want to find more bugs and find them quickly, check out our new Diligence fuzzing service (powered by Harvey)!
Thanks to Joran Honig and Tobias Vogel for feedback on drafts of this article.
Thinking about smart contract security? We can provide training, ongoing advice, and smart contract auditing. Contact us.