Targeted fuzzing using static lookahead analysis: how to guide fuzzers using online static analysis
In previous posts, we introduced Harvey, a fuzzer for Ethereum smart contracts, and presented two techniques to boost its effectiveness: input prediction and multi-transaction fuzzing.
Harvey is being developed by MythX in collaboration with Maria Christakis from MPI-SWS. It is one of the tools that powers our smart contract analysis service. Sign up for our free plan to give it a try!
In this post, we summarize our upcoming ICSE 2020 paper and provide a high-level overview of how we use online static analysis to guide Harvey. If you are not familiar with fuzzing we suggest to check out the above post since we will assume some basic background below.
Targeted fuzzing
Let’s assume that there are specific target locations in a program you want to fuzz. For example, these could be locations that were recently modified or contain assertions that should be checked. Or maybe a static analyzer has reported warnings for these locations.
The goal of targeted fuzzing is to generate inputs that explore these locations as quickly and frequently as possible. This is challenging since the fuzzer cannot easily predict if a given input explores locations that are “close” to a target location. Unfortunately, the fuzzer only knows which locations are actually explored by the input.
To help the fuzzer with this task, we perform a static lookahead analysis for each input that is added to its queue of “interesting”; inputs. The fuzzer uses this (cyclic) queue to select the next input that will be fuzzed and typically adds inputs that increase coverage.
Lookahead Analysis
The diagram below illustrates the idea behind this novel analysis. Given an input that explores a program path π (bold in the diagram), we consider several so-called split points P1 to Pn along that path. For each of these points Pi, starting from P1, we perform a light-weight static analysis that involves two steps.
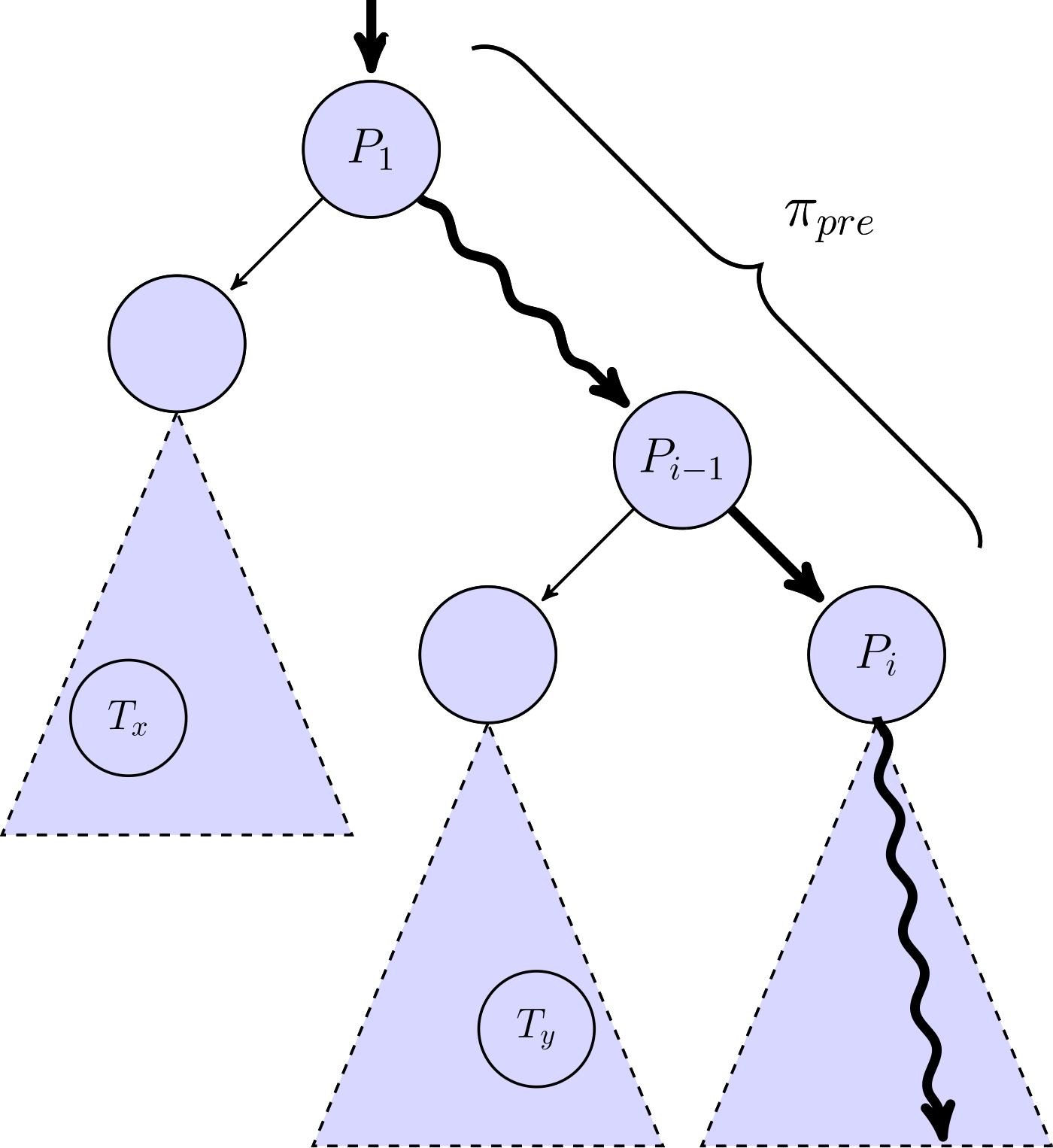
First, we consider the prefix πpre of the entire program path π that ends at split point Pi. We compute a condition ϕ that over-approximates all the program states at the split point when executing the prefix. We then check if any target locations are reachable when starting from Pi in a program state that satisfies the condition ϕ. In other words, we check if there are any program paths (with prefix πpre) that reach a target location. In the diagram, the triangles represent sets of paths.
As soon as no targets are found in the second step, we stop the lookahead analysis and we consider the corresponding prefix πpre to be a so-called no-target-ahead prefix. The fuzzer records the split points along this prefix and computes a lookahead identifier by hashing the prefix. For instance, in the diagram above πpre is a no-target-ahead prefix since none of the targets Tx and Ty are reachable from split point Pi.
The lookahead identifier is similar to the path identifier that a greybox fuzzer computes based on which control-flow edges are traversed when executing a given input (see our post on greybox fuzzing for more details). Observe however, that two inputs with different path IDs may share the same lookahead ID if both exercise the same no-target-ahead prefix.
In our implementation, we use Bran, an abstract interpreter for EVM bytecode, to perform the static analysis. Since this analysis runs frequently it needs to be very efficient and light-weight.
Adapting the greybox fuzzing algorithm
Let’s see how we can use this additional information - the split points and the lookahead identifier - to guide the fuzzer. Before that, we will quickly recap the standard greybox fuzzing algorithm below:
// We set up the initial queue by executing the program P for the seed inputs S.
Q := run_seed_inputs(P, S)
while (running) {
i := select_input(Q)
e := assign_energy(i) // Adaptation: We assign energy based on lookahead information.
while (0 < e) {
f := fuzz_input(i)
pid := run_input(P, f)
if pid not in Q {
Q[pid] := f
// Adaptation: We will run the lookahead analysis for input i.
}
e := e - 1
}
}
The fuzzer initially runs the program P with the seed inputs S to initialize the queue Q. While the fuzzer is running, it keeps selecting inputs that will be fuzzed from the queue. It uses a function assign_energy to determine how often a selected input is fuzzed.
When a fuzzed input discovers a new path ID, it is added to the queue (here, a simple map from path ID to input). This is where we run the lookahead analysis (see third comment) to gather additional information about this newly discovered input.
We use this information to adjust how much energy we assign to it in the future (see second comment). We will assign more energy if (1) the input’s no-target-ahead prefix was rarely executed, or (2) any of its split points were rarely executed.
Intuitively, the lookahead ID groups (or partitions) the inputs in the queue since multiple inputs may share the same lookahead ID. The above energy schedule aims to prevent the fuzzer from spending disproportionate amounts of energy on a few partitions that contain many inputs. The split points partition the queue in a similar way and both factors turn out to be important in practice. The key insight is that the fuzzer gains more from discovering inputs that explore new lookahead IDs or new split points than ones that explore existing ones.
Evaluation
We evaluated the effectiveness of this approach on 27 real-world smart contracts and found that the fuzzer was able to reach 83% of the challenging target locations significantly faster (with a speedup of up to 14x). We also found that the overhead of the static analysis was very low (~3s per fuzzing campaign).
In this post, we provided a high-level overview of how we use online static analysis to guide Harvey. For more details please check out our upcoming ICSE 2020 paper.
Thanks to Maria Christakis and Joran Honig for feedback on drafts of this article.
Thinking about smart contract security? We can provide training, ongoing advice, and smart contract auditing. Contact us.